
性能对齐海外领军闭源模型
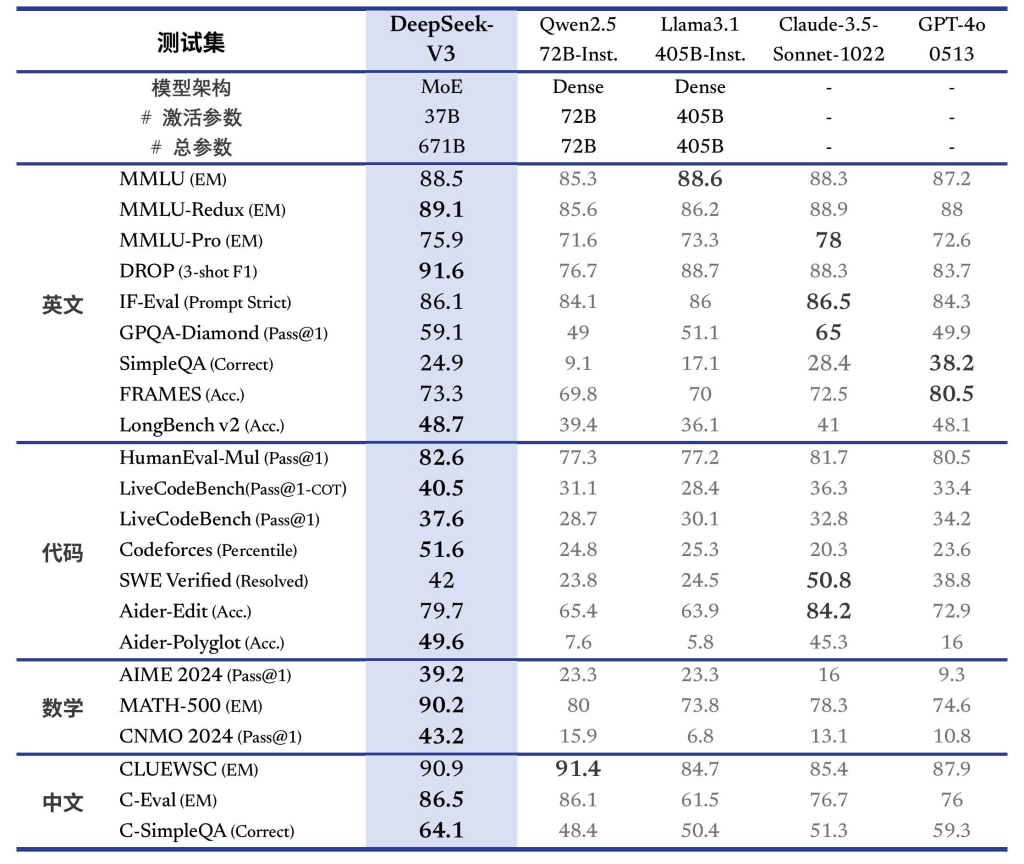
DeepSeek-V3 为自研 MoE 模型,671B 参数,激活 37B,在 14.8T token 上进行了预训练。
论文链接:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
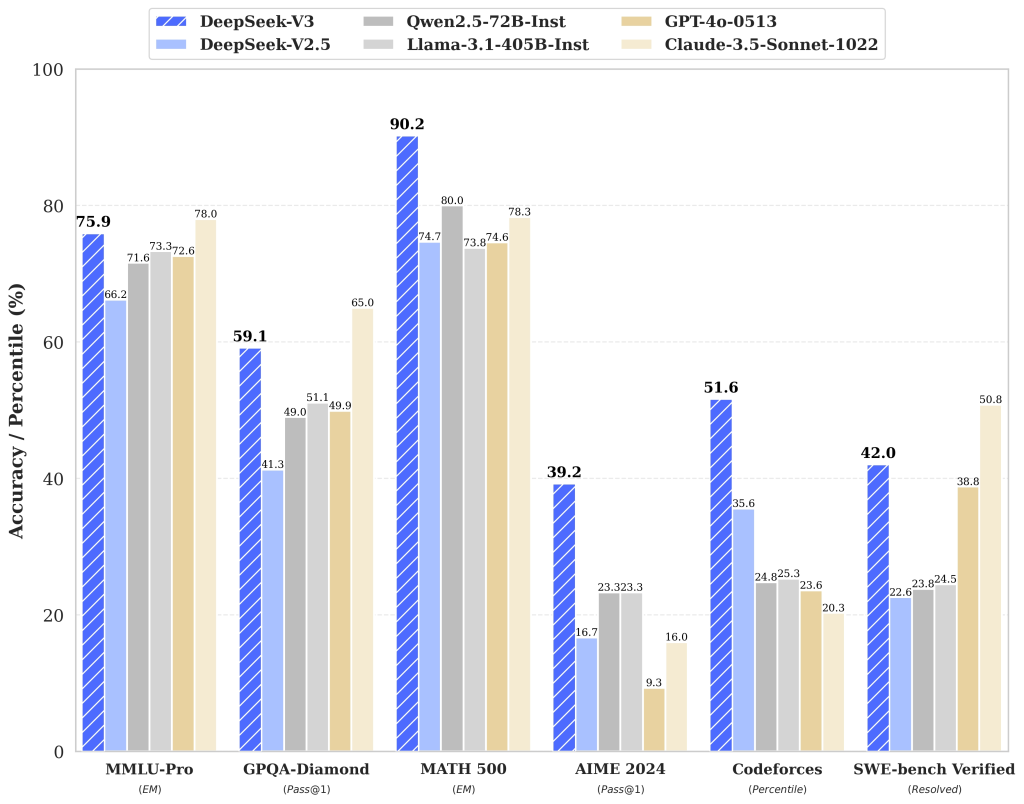
- 百科知识: DeepSeek-V3 在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代 DeepSeek-V2.5 显著提升,接近当前表现最好的模型 Claude-3.5-Sonnet-1022。
- 长文本: 在长文本测评中,DROP、FRAMES 和 LongBench v2 上,DeepSeek-V3 平均表现超越其他模型。
- 代码: DeepSeek-V3 在算法类代码场景(Codeforces),远远领先于市面上已有的全部非 o1 类模型;并在工程类代码场景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
- 数学: 在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3 大幅超过了所有开源闭源模型。
- 中文能力: DeepSeek-V3 与 Qwen2.5-72B 在教育类测评 C-Eval 和代词消歧等评测集上表现相近,但在事实知识 C-SimpleQA 上更为领先。
生成速度提升至 3 倍
通过算法和工程上的创新,DeepSeek-V3 的生成吐字速度从 20 TPS 大幅提高至 60 TPS,相比 V2.5 模型实现了 3 倍的提升,为用户带来更加迅速流畅的使用体验。
开源权重和本地部署
DeepSeek-V3 采用 FP8 训练,并开源了原生 FP8 权重。
得益于开源社区的支持,SGLang 和 LMDeploy 第一时间支持了 V3 模型的原生 FP8 推理,同时 TensorRT-LLM 和 MindIE 则实现了 BF16 推理。此外,为方便社区适配和拓展应用场景,我们提供了从 FP8 到 BF16 的转换脚本。
模型权重下载和更多本地部署信息请参考: https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
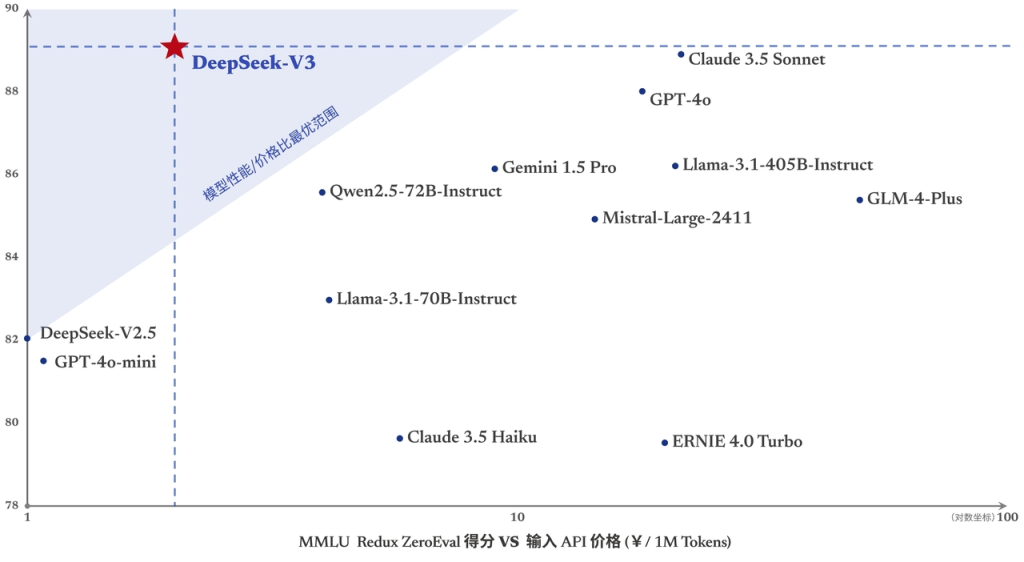
“以开源精神和长期主义追求普惠 AGI” 是 DeepSeek 一直以来的坚定信念。我们非常兴奋能与社区分享在模型预训练方面的阶段性进展,也十分欣喜地看到开源模型和闭源模型的能力差距正在进一步缩小。
这是一个全新的开始,未来我们会在 DeepSeek-V3 基座模型上继续打造深度思考、多模态等更加丰富的功能,并将持续与社区分享我们最新的探索成果。
